


تعريف
قبل أن نتطرق لتعريف البيانات الضخمة، علينا اولاً أن نعرف ما هي البيانات، وما اختلافها عن المعلومات.
البيانات هي الشكل الخام لأي محتوى ننتجه، مثلاً لو كان لديك عشرة أشخاص وقمت بقياس أطوالهم وسجلتها على ورقة، هذه الورقة تحوي بيانات.
المعلومات هي مخرجات أية عملية معالجة للبيانات الخام, بمعنى لو اخذت أطول هؤلاء الأشخاص العشرة وقمت بالحصول على متوسط حسابي لها، هذا المتوسط هو معلومة، لأنه يعطي مقياس مفيد. بينما البيانات مجرد أرقام مسجلة على ورقة.
عرف معهد ماكنزي العالمي سنة 2011 البيانات الضخمة أنها أي مجموعة من البيانات التي هي بحجم يفوق قدرة أدوات قواعد البيانات التقليدية من إلتقاط، تخزين، إدارة و تحليل تلك البيانات.
وتتألف البيانات الضخمة من كل من المعلومات المنظمة والتي تشكل جزء ضئيل يصل إلى 10% مقارنة بالمعلومات غير المنظمةوالتي تشكل الباقي.
والمعلومات غير المنظمة هي ما ينتجه البشر، كرسائل البريد الإلكتروني، مقاطع الفيديو، التغريدات، منشورات فيس بوك، رسائل الدردشة على الواتساب، النقرات على المواقع وغيرها.
البيانات الضخمة Big data أصبحت واقع نعيشه، حتى أن قاموس أوكسفورد اعتمد المصطلح و أضافه للقاموس مع مصطلحات مستحدثة أخرى مثل التغريدة tweet.
كم يعني ضخمة؟
ما هو ضخم اليوم، لن يكون كذلك غداً. وما هو ضخم بالنسبة لك، يعد صغيراً جداً لغيرك. وهنا يبرز التحدي لتعريف معنى الضخم.
ومنذ العام الماضي كانت الحدود المفروضة على حجم مجموعات البيانات الملائمة للمعالجة في مدة معقولة من الوقت خاضعة لوحدة قياس البيانات إكسابايت.
تقدر أبحاث شركة إنتل أن حجم البيانات التي ولدها البشر منذ بداية التاريخ وحتى عام 2003 ما قدره 5 إكسابايت، لكن هذا الرقم تضاعف 500 مرة خلال عام 2012 ليصل إلى 2.7 زيتابايت، ويتوقع أن يتضاعف هذا الرقم أيضاً ثلاث مرات حتى عام 2015.
مثال: طائرة ايرباص A380 تنتح مليار سطر من الشيفرات البرمجية كل نصف ساعة، أو لنقل 10 تيرابايت من البيانات، هذه البيانات تولدها المحركات والحساسات في الطائرة عن كل التفاصيل الدقيقة المصاحبة لرحلتها، و تذكر هذه مجرد نصف ساعة في رحلة واحدة فقط من طائرة واحدة فقط.
وبالمثل فلو سافرت بالطائرة في رحلة من مطار هيثرو إلى مطار كيندي، فإن الرحلة سينتج عنها 640 تيرابايت من البيانات. فتخيل كم رحلة تقطعها الطائرات يومياً، ومنه ستتخيل طبيعة حجم البيانات الضخمة. وبهذه المقاييس فإن كل ما كنا نعرفه على أنه بيانات ضخمة، يصبح قزماً.
و يقوم كل فرد منا بإطلاق 2.2 مليون تيرا بايت من البيانات يومياً، و هناك 12 تيرابايت من التغريدات يومياً مع 25 تيرابايت من سجلات الدخول على فيس بوك يومياً و على تويتر أكثر من 200 مليون مستخدم نشط يكتبون أكثر من 230 مليون تغريدة يوميا.
حجم البيانات كان في 2009 حوالي 1 زيتا بايت ( تريليون غيغابايت ) و في 2011 ارتفع إلى 1.8 زيتا بايت
تقول IBM إننا ننتج 2.5 كوينتيليون بايت من البيانات كل يوم (الكوينتيليون هو الرقم واحد متبوعاً بـ18 صفراً). هذه البيانات تنبع من كل مكان، مثل المعلومات حول المناخ والتعليقات المنشورة على مواقع التواصل الاجتماعي والصور الرقمية والفيديوهات ومعاملات البيع والشراء
تعد البيانات الضخمة الجيل القادم من الحوسبة والتي تعمل على خلق القيمة من خلال مسح وتحليل البيانات.
ومع مرور الزمن أصبحت البيانات التي ينتجها المستخدمين تنمو بشكل متسارع لعدة أسباب، منها بيانات المشتريات في محلات السوبر ماركت و الأسواق التجارية و فواتير الشحن و المصارف و الصحة والشبكات الإجتماعية.
ومع تطوير تقنيات التعرف على الوجه و الأشخاص، فإنها ستتمكن من العثور على المزيد من التفاصيل والمعلومات عن أي شخص، ومع تزايد عدد الأجهزة المتصلة بالإنترنت، الأجهزة التي لم نعتد عليها أن تتصل بالشبكة العالمية مثل السيارات و البرادات و الغسالات فإنها كلها تساهم في زيادة حجم البيانات المنتجة.
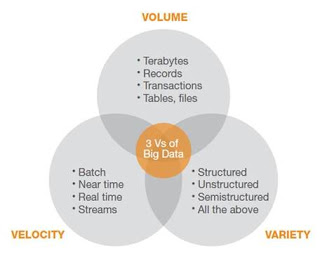
خصائص البيانات الضخمة
وحتى تكون البيانات ضخمة يجب توفر ثلاثة عوامل رئيسية:
- الحجم: وهو عدد التيراباتيت من البيانات التي نطلقها يومياً من المحتوى.
- التنوع: وهو تنوع هذه البيانات ما بين مهيكلة وغير مهيكلة ونصف مهيكلة
- السرعة: مدى سرعة تواتر حدوث البيانات، مثلاً تختلف سرعة نشر التغريدات عن سرعة مسح أجهزة الاستشعار عن بعد لتغييرات المناخ.
لكن ما هي خصائص البيانات الضخمة؟ يتم تمييز البيانات الضخمة من خلال الحجم، التنوع، و السرعة. ومن خلال دراسة الحجم الكبير للبيانات يمكن للشركات أن تفهم زبائنها بشكل أفضل، تخيل مثلاً البحث في بيانات مشتريات مليون شخص يتعامل مع متجر وول مارت، هذا البحث والتحليل في الكم الهائل من فواتير المشتريات وتكرار المشتريات و تنوعها، سيعطي معلومات مفيدة جداً للإدارة ومتخذي القرار.
وتبرز التحديات أمام أدوات إدارة قواعد البيانات التقليدية في التعامل مع البيانات المتنوعة و السريعة، حيث كانت قواعد البيانات التقليدية تتعامل مع المستندات النصية و الأرقام فقط، أما البيانات الضخمة اليوم تحوي أنواع جديدة من البيانات التي لا يمكن تجاهلها، كالصور و المقاطع الصوتية و الفيديو و النماذج ثلاثية الأبعاد وبيانات المواقع الجغرافية وغيرها.
ومع تزايد حجم وتنوع البيانات التي تتعامل معها الشركات اليوم وجدت نفسها أمام طريقين، إما تجاهل هذه البيانات، أو البدء بالتكيف معها تدريجياً لفهمها والإستفادة منها. لكن مع إستخدام الأدوات التقليدية المتبعة سابقاً لا يمكنك تحليل و الإستفادة من هذه البيانات الجديدة الضخمة.
وعلى سبيل المثال فإن غالبية المتاجر الضخمة و الأسواق التجارية التي تتعامل مع بطاقات الولاء، لا تستفيد من هذه البيانات وتعالجها بطريقة تساعدها على فهم المشترين بشكل أفضل لتطوير نموذج بطاقات الولاء.
وأيضاً كل مقاطع الفيديو التي تسجلها الأجهزة الطبية خلال العمليات الجراحية، لا يتم الإستفادة منها بالشكل المطلوب، بل ويتم حذفها خلال أسابيع.
واليوم تعد Hadoop من أفضل تقنيات التعامل مع البيانات الضخمة، وهي مكتبة مفتوحة المصدر مناسبة للتعامل مع البيانات الضخمة المتنوعة و السريعة، وتستخدم شركات كبرى خدمة Hadoop، مثلاً هناك لينكدإن الشبكة الإجتماعية المتخصصة بالوظائف والعمل تستخدم الخدمة من أجل توليد أكثر من 100 مليار مقترح على المستخدمين أسبوعياً.
لكن ما الفائدة من البيانات الضخمة؟ تقول IBM أن البيانات الضخمة تعطيك فرصة إكتشاف رؤى مهمة في البيانات، وتقول أوراكل أن البيانات الضخمة تتيح للشركات أن تفهم بعمق أكثر زبائنها.
قدرت شركة سيسكو أنه وبحلول عام 2015 فإن حركة الزيارات على الإنترنت بالشكل الإجمالي ستتجاوز 4.8 زيتابايت ( أي 4.8 مليار تيرا بايت ) سنوياً.
لماذا يجب أن نهتم بالبيانات الضخمة؟
والسبب الأهم لزيادة حجم البيانات، لأنها تستمر بالتولد بشكل أكبر بكثير من السابق من خلال عدة أجهزة ومصادر, و الأهم أن معظم تلك البيانات ليست مهيكلة، كتغريدات تويتر و الفيديوهات على يوتيوب و تحديثات الحالة على فيس بوك وغيرها، ما يعني أنه لا يمكن إستخدام أدوات إدارة قواعد البيانات و تحليلها التقليدية مع هذه البيانات لأنها ببساطة ليست وفق الهيكل الذي تتعامل معه كجداول.
لكن هل تستحق البيانات الضخمة عناء الإهتمام بها؟ لما لا نتجاهلها وحسب؟ .. تشير الدراسات من غارتنر أن هناك حوالي 15% فقط من الشركات التي تستفيد بشكل جيد من البيانات الضخمة، لكن هذه الشركات حققت فعالية 20% أكثر في المؤشرات المالية.
لكن حتى تصل لهذه النتيجة التي لا يحققها منافسيك، عليك إستخدام تقنيات ومفاهيم جديدة إبداعية مخصصة للتعامل مع البيانات الضخمة. لأن الأمر أشبه بجبل شاهق من البيانات ستقوم بغربلته لتحصل على صخرة ذهبية وزنها كيلوغرام واحد.
تخيل أن هناك شركة نقل وشحن وتقوم بالتنقيب في بيانات مواعيد شاحنات نقل البضائع بحيث تحصل على البيانات في الزمن الفعلي لمواعيد إطلاق و وصول الشاحنات وفق عدة مواقع جغرافية أو مدن او حتى دول. والآن تخيل لو أن أحد الزبائن اتصل بالشركة و أخبرهم أن لديه شحنة، أي شاحنة سترسل إليه من الأسطول المكون من مئات الشاحنات التي تدير الأعمال في المدينة؟ المنطق يكون أن ترسل أقرب شاحنة وذلك وفق تتبعها عبر GPS، لكن ماذا لو كان الطريق أمام أقرب شاحنة مزدحماً جداً، أو لو كانت أقرب شاحنة ممتلئة بالكامل ولا مجال لإضافة شحنة أخرى، في هذه الحالة لن يكون الإختيار الأقرب هو الأنسب لذا علينا إجراء تحليل على كل الشاحنات المتاحة وفق عدة معايير، وهذه المعايير نطبقها على البيانات التي تصدرها تلك الشاحنات، مثل بيانات حركتها و موقعها الحالي عبر GPS، إزدحام الطريق، وزن و حجم و نوع الحمولة، الوجهة التالية، وغيرها. وهذا التحليل تقوم به أدوات متخصصة تصدرها شركات كبرى مثل إنتل و IBM وغيرها، تعمل على تحليل البيانات الضخمة في الزمن الحقيقي.
أمثلة عملية
- مصادم الهيدرون العظيم يملك 150 مليون جهاز استشعار تقدم بيانات 40 مليون مرة في الثانية الواحدة. وهناك ما يقرب من 600 مليون تصادم في الثانية الواحدة. لكن نتعامل فقط مع أقل من 0.001% من بيانات تيار الاستشعار، فإن تدفق البيانات من جميع تجارب المصادم الأربعة يمثل 25 بيتابايت.
- موقع Amazon.com يعالج ملايين العمليات الخلفية كل يوم، فضلاً عن استفسارات من أكثر من نصف مليون بائع طرف ثالث. وتعتمد أمازون علي نظام اللينوكس بشكل أساسي ليتمكن من التعامل مع هذا الكم الهائل من البيانات، و تملك أمازون أكبر 3 قواعد بيانات لينوكس في العالم والتي تصل سعتها إلي 7.8، 18.5 و 24.7 تيرابايت.
- سلسلة المتاجر Walmart تعالج أكثر من مليون معاملة تجارية كل ساعة، والتي يتم استيرادها إلي قواعد بيانات يُقدر أنها تحتوي علي أكثر من 2.5 بيتابايت (2560 تيرابايت) من البيانات – وهو ما يوازي 167 ضعف البيانات الواردة في جميع الكتب الموجودة في مكتبة الكونغرس في الولايات المتحدة.
- يعالج فيس بوك 50 مليار صورة من قاعدة مستخدميه. ويقوم نظام حماية بطاقات الائتمان من الاحتيال ” FICO Falcon Credit Card Fraud Detection System” بحماية 2.1 مليار حساب نشط في جميع أنحاء العالم.
- تقوم شركة Windermere Real Estate باستخدام إشارات GPS مجهولة من ما يقرب من 100 مليون سائق لمساعدة مشتري المنازل الجدد لتحديد أوقات قيادتهم من وإلى العمل خلال الأوقات المختلفة لليوم.
عالم التقنية


 رد مع اقتباس
رد مع اقتباس