


طريقة جديدة للتعلم الروبوتي ذاتي المراقبة تتضمن وضع أهداف قابلة للتحقيق
أثبتت تقنية التعلم المعزز Reinforcement Learning (RL) فاعليتها في تدريب العملاء الاصطناعيين artificial agents على مهام فردية، ومع ذلك، ما تزال معظم مقاربات التعلم المعزز الموجودة محدودة الفاعلية حين يتعلق الأمر بتدريب روبوتات متعددة الأغراض قادرة على إتمام عدد من المهام التي تتطلب مهارات مختلفة.
ولمحاولة التغلب على هذا التحدي، طور فريق من الباحثين من جامعة كاليفورنيا، بيركلي مقاربةً جديدةً للتعلم المعزز يمكن استعمالها لتعليم الروبوتات كيف تُكيف سلوكها بناءً على المهمة المطلوبة. لُخصت المقاربة في ورقة بحثية نُشرت في أرشيف arXiv، وعُرضت في مؤتمر التعلم الروبوتيConference on Robot Learning.
تسمح نقاربة التعلم المعزز هذه للروبوتات بالتوصل تلقائيًا إلى أفعال وممارستها مع مرور الوقت، وأن تتعلم أيًا من هذه الأفعال يمكن استخدامها في بيئة معينة، وبذلك تستطيع الروبوتات إعادة توظيف المعارف التي اكتسبتها، وتطبيقها لإتمام مهام جديدة يُسندها إليها مستخدمون بشريون.
العملاء الاصطناعيون artificial agents: كيانات ذكية ذاتية الحركة، تعمل على تحقيق أهداف محددة في بيئة معينة بالاعتماد على أجهزة استشعار ومحركات. قد تكون هذه الكيانات بسيطة أو معقدة، وقد تكون قادرة على التعلم أو استعمال المعرفة لتحقيق أهدافها. يُعتبر جهاز تنظيم الحرارة Thermostat مثالًا لعميل اصطناعي.
أرشيف arXiv: هو أرشيف لمسودات أوراق علمية إلكترونية مكتوبة في مجالات الفيزياء، والرياضيات، والفلك، وعلم الحاسوب، والإحصاء، والتي يمكن الوصول إليها عبر الإنترنت. هذه الأرشيفات موجودة على موقع arXiv.org.
صرح آشفين نير Ashvin Nair، الباحث المشارك في الدراسة، في حديثه إلى شبكة TechXplore: «نحن نعلم أن البيانات هي مفتاح التحكم الروبوتي، وللحصول على قدرٍ كاف من البيانات لتحقيق هذا التحكم، سيكون على الروبوتات أن تجمع البيانات بأنفسها؛ هذا ما نسميه التعلم الروبوتي ذاتي المراقبة self-supervised robot learning، وفيه يكون الروبوت قادرًا على جمع بيانات استكشاف متسقة، ويستنتج بنفسه إذا كان قد نجح أو فشل في أداء المهمة، ويتعلم بذلك مهارات جديدة».
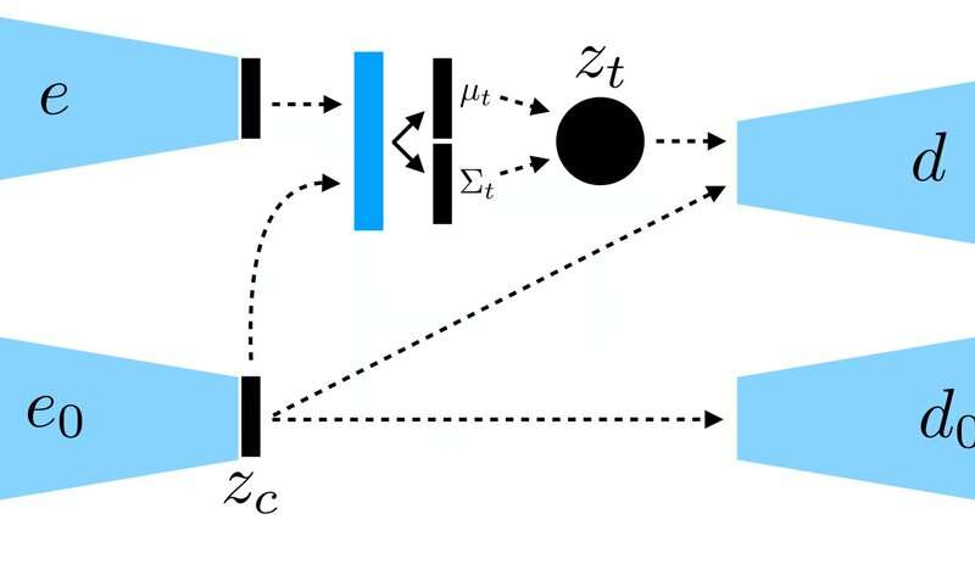
تعتمد المقاربة الجديدة على إطار التعلم المعزز المرتبط بأهداف goal-conditioned RL framework الذي قدمه الفريق ذاته سابقًا، وفيه استخدم الباحثون تقنية تحديد الأهداف في مساحة كامنة، لتدريب الروبوت على مهارات مثل دفع الأجسام أو فتح الأبواب، مباشرةً من خلال بيكسلات، دون الحاجة إلى نظام مكافآت خارجية أو تقدير للحالة.
درب الباحثون جهاز تشفير آلي متغير VAE مشروط السياق على البيانات، لينفصل عن السياق ويبقى ثابتًا في أثناء التشغيل
أوضح نير: «نركز في عملنا الجديد على التعميم Generalization، كيف يمكننا تحقيق تعلم ذاتي المراقبة، لا لتعلم مهارة جديدة فقط، بل أيضًا للتمكن من تعميم التنوع البصري visual diversity في أثناء ممارسة هذه المهارة؟ نحن نعتقد أن القدرة على التعميم في المواقف الجديدة ستكون مفتاحًا لتحقيق تحكم روبوتي أفضل».
عوضًا عن تدريب الروبوت على عدة مهارات منفردة، صمم نير وفريقه نموذج تحديد الأهداف الشَرطي conditional goal-setting model لتحديد أهداف محددة قابلة للتحقيق ومتناسبة مع حالة الروبوت. تتعلم الخوارزمية التي طورها الباحثون نمطًا محددًا من التمثيل، يفصل بين الأمور التي يستطيع الروبوت أن يتحكم بها، وتلك التي لا يستطيع التحكم بها.
تستند تقنية التعلم ذاتي المراقبة إلى أن يجمع الروبوت البيانات بدايةً في هيئة صور وأفعال، عبر تفاعله مع البيئة المحيطة، ثم يدرب الروبوت تمثيلًا مضغوطًا compressed representation من هذه البيانات، يحول الصور إلى متجهات محدودة الأبعاد تحتوي ضمنيًا معلومات مثل مواضع الأجسام، وبهذا، عوضًا عن تعليم الروبوت مباشرةً ما يجب عليه أن يتعلمه، يستوعب هذا التمثيل المفاهيم تلقائيًا من طريق ضغط أهدافه.
شرح نير: «باستخدام التمثيل المكتسَب، يستطيع الروبوت بلوغ أهداف مختلفة، وتطوير سياسة تستخدم التعلم المعزز. يُعد التمثيل المضغوط أساسًا لمرحلة الممارسة، ويُستعمل لقياس مدى التشابه بين صورتين ليعرف الروبوت إذا كان قد نجح أو فشل، ويُستعمل لتمثيل الأهداف حتى يستطيع الروبوت تحقيقها، وبهذا يستطيع الروبوت عند الاختبار أن يطابق صورة هدف محدد من قبل إنسان عبر تنفيذ السياسة التي تعلمها».
يجمع الروبوت بيانات من التفاعل العشوائي لتُستخدم لتدريب تمثيل، باعتبارها بيانات خارج سياسة التعلم المعزز
قيّم الباحثون فاعلية مقاربتهم باستخدام سلسلة من التجارب يعالج فيها الروبوت أجسامًا يراها لأول مرة في بيئة أُنشئت باستخدام منصة المحاكاة MuJuCo، ومن المثير للاهتمام أن طريقتهم في التدريب قد مكّنت الروبوت من أن يكتسب تلقائيًا مهارات يمكن تطبيقها في مواقف جديدة.
بصورة أكثر تحديدًا، تمكن الروبوت من التعامل مع مجموعة متنوعة من الأجسام، بتعميم استراتيجيات التعامل التي اكتسبها سابقًا على أجسام جديدة لم يقابلها في مرحلة التدريب.
قال نير: «نحن متحمسون جدًا للنتائج التي توصلنا إليها. وجدنا أولًا أنه بإمكاننا تدريب سياسة لدفع أجسام في العالم الحقيقي، حتى 20 جسمًا تقريبًا، لكن حقيقةً يمكن للسياسة المكتسَبة أن تدفع المزيد من الأجسام. هذا النوع من التعميم هو الهدف الرئيسي لطرق التعلم العميق، ونأمل أن يكون بدايةً لصور أكثر تقدمًا من التعميم».
من اللافت للنظر أن نير وزملاءه قد تمكنوا في أثناء تجاربهم من تدريب سياسة باستخدام مجموعة محددة من بيانات التفاعلات، دون الحاجة إلى جمع كم كبير من البيانات من الإنترنت، الأمر الذي يُعد إنجازًا مهمًا، لأن جمع البيانات من أجل الأبحاث المماثلة أمرٌ مكلف للغاية، وقدرة نموذجهم على تعلم مهارات من مجموعات محددة من البيانات يجعل مقاربتهم أكثر عمليةً بكثير.
إن نموذج التعلم ذاتي المراقبة الذي طوره الفريق قد يمكّن الروبوتات في المستقبل من معالجة مجموعة أوسع من المهام، دون الحاجة إلى التدريب على مجموعة كبيرة من المهارات المنفردة. في نفس الوقت، يخطط نير وزملاؤه لاختبار مقاربتهم في بيئات محاكاة، بينما يبحثون عن طرق لتحسينها.
أشار نير: «نتابع الآن البحث على محاور مختلفة، تتضمن حل المهام باستخدام كم أكبر من التنوع البصري، وحل مجموعة كبيرة من المهام بشكل متزامن، ونبحث إمكانية استخدام حل مهمة ما في تسريع حل المهمة التالية».


 رد مع اقتباس
رد مع اقتباس